


I. Introduction▲
Ce document vous présente les nombreux avantages liés à l'utilisation de la version 8 dans l'environnement Windows. La liste des points évoqués dans ce document devrait vous permettre de mettre en valeur et de tirer parti de votre système d'exploitation.
Nous verrons dans une première partie la manière d'exploiter au mieux votre serveur dans un mode Client/Serveur classique, surtout dans le cas où votre serveur dispose de plusieurs processeurs. Pour ce faire nous utiliserons deux fonctionnalités du module SAS/CONNECT : le mode asynchrone et le MP CONNECT.
La seconde partie nous donnera l'occasion de parler d'un autre type de serveur lié aux architectures centralisées dans l'environnement Terminal Server Edition et intégrées aujourd'hui dans les services de Windows 2000.
La dernière partie aura pour contenu les sécurités utilisées par le système SAS avec dans ce domaine de nouvelles options que ce soit en terme de connexion (SAS/CONNECT) ou en terme de partage de données (SAS/SHARE). Nous dirons quelques mots du module SAS/SECUREâ et verrons enfin comment franchir un firewall avec une nouvelle option du programme Spawner (INHERITANCE).
II. Comment tirer parti de l'architecture SMP ?▲
II-A. Le mode Asynchrone SAS/CONNECT et MP CONNECT▲
Les serveurs évoluent rapidement en terme de puissance : la version Data Center de la famille Windows 2000 devrait ainsi utiliser jusqu'à 32 processeurs et 64 Go de mémoire vive.
Le client SAS, exécutant une application en mode Client/Serveur, démarre une session SAS sur le serveur : en terme système, on parle d'un processus SAS.EXE. Ainsi nous pouvons constater que le nombre de processus actifs sur le serveur est identique au nombre de clients utilisant l'application. Si un processus SAS utilise un seul processeur, l'ensemble des processus en cours se partage le ou les processeurs présents sur la machine. Dans ce cas de figure, on obtient une bonne répartition de la charge sur la totalité des processeurs. Il en est autrement si un seul processus SAS est actif, car il n'utilise qu'un seul processeur. C'est la raison de la nouvelle fonctionnalité nommée MP CONNECT et introduite dans le module SAS/CONNECT. MP CONNECT vous permet une exécution parallèle de tâches distinctes et présentes dans un même programme SAS. Cette fonctionnalité permet le démarrage d'un autre processus SAS et donc d'utiliser au mieux vos architectures SMP.
Le terme de multi-processing indique qu'un code peut être découpé en unités indépendantes pouvant s'exécuter parallèlement. En terme système on parle de « thread ». Le système SAS est une application utilisant un seul thread actif et s'exécute donc sur un seul processeur même si votre serveur est équipé de plusieurs processeurs.
Si l'on souhaite découper un code SAS, il faut d'abord que chaque partie de ce code puisse s'exécuter indépendamment des autres parties. Une fois ce découpage effectué, MP CONNECT fournit des instructions simples pour le lancement des processus SAS et la synchronisation de ces derniers.
Chaque nouveau processus hérite des permissions et des droits du processus père et, en ce qui concerne SAS, une nouvelle bibliothèque WORK est allouée. Bien entendu on utilise pour le lancement de la nouvelle session le mode asynchrone, qui permet de poursuivre le traitement dans le programme SAS initial.
Prenons un cas simple : on souhaite effectuer le rapprochement de deux tables SAS. Pour ce faire l'une et l'autre des tables doivent être triées avant l'exécution de l'étape de fusion ; les deux tris sont indépendants et on peut, dans ce cas, les faire parallèlement. Il faudra bien entendu s'assurer que les deux tris soient terminés avant d'effectuer la fusion.
Les graphes suivants sont issus de tests effectués dans nos laboratoires de tests aux USA. Vous trouverez en annexe le programme de test. Il est exécuté plusieurs fois sur la même machine. En abscisse vous trouverez le temps d'exécution, et en ordonnée le nombre de processeurs (courbe MPC) ou d'itérations (courbe SERIAL).
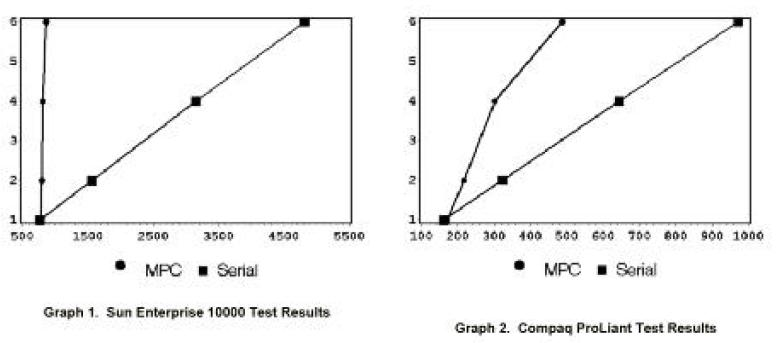
Les gains sont très importants quand on utilise jusqu'à six processeurs. De plus les courbes MPC obtenues sont presque linéaires. La répartition obtenue est donc bonne.
Remarques auxquelles il faudra faire attention :
- Tous les programmes ne peuvent être découpés et la duplication de tables pour permettre la parallélisation des traitements peut entraîner un surplus de ressources nécessaires sur le serveur.
- Il faudra être vigilant sur l'utilisation des ressources non-partageables.
- La puissance CPU n'est pas tout. Si l'on multiplie le nombre de processus actifs, d'autres paramètres liés directement aux performances doivent être sous surveillance, notamment les Entrées/Sorties effectuées sur disque.
II-B. Le fonctionnement▲
L'option SASCMD vous permet d'indiquer la commande SAS qui sera exécutée. Cette option peut être positionnée avec le SIGNON ou encore RSUBMIT dans le cas où vous utilisez le mode AUTOSIGNON.
L'option CWAIT=NO permet de démarrer de nouvelles connexions asynchrones.
Le dernier ordre important est le WAITFOR : il offre la possibilité d'attendre la fin d'exécution de la tâche qui a été démarrée. Cette instruction peut prendre les valeurs _ANY_ , _ALL_ ou nom_tâche indiquant respectivement l'attente de fin d'exécution de l'une des tâches, de toutes ou de celle spécifiée. NB : la commande LISTASK vous permet de lister à tout moment les tâches actives.
Pour conclure sur cette partie, il est important de noter qu'un réaménagement de vos programmes peut améliorer grandement les performances. Le découpage effectué, très peu d'instructions seront nécessaires pour utiliser au mieux votre architecture SMP.
III. Le système SAS et les architectures centralisées▲
Que l'on parle de Terminal Server Edition ou encore de Citrix, l'une des premières questions que l'on se pose est de savoir si le système SAS peut s'installer dans ce type d'environnement. La réponse est OUI. Mais dans quelle mesure cela est-il bénéfique et quelles sont les précautions à prendre lors de l'installation du système SAS ?
III-A. Les avantages d'une architecture centralisée▲
La baisse du coût global de possession (TCO pour les anglo-saxons) est sans doute le premier atout de ce type d'environnement. Ce coût global comporte plusieurs composantes qui sont le coût des logiciels et du matériel (loués ou achetés), le coût du support et de la maintenance, le coût de l'installation du logiciel et enfin les coûts liés à la formation sur le produit. En dehors de ces derniers cités, l'ensemble de ces coûts est grandement diminué par l'utilisation d'une architecture centralisée.
Le second avantage est la gestion du parc informatique. Son évolution peut se faire en douceur, car seul le serveur doit faire l'objet de toutes les attentions. Toutes les applications sont installées sur le serveur et il suffit ensuite de les publier vers les postes utilisateurs. Ceuxci exécutent leurs programmes sur le serveur qui ne leur renvoie que les différents affichages faits sur l'écran.
Le dernier point est la mise à disposition de l'application à travers un réseau à faible débit. En effet, lorsque les postes clients se connectent en mode Client/Serveur en utilisant une bande passante très faible, on constate immédiatement des temps de réponse dégradés. Les protocoles utilisés dans une architecture centralisée (RDP ou ICA) sont peu gourmands en bande passante sur le réseau. Ceci permet un déploiement d'applications sur des postes éloignés du serveur.
III-B. L'installation du système SAS▲
La différence avec une installation classique est que l'ensemble des éléments installés soit disponible pour tous les utilisateurs et non pas pour un seul. Il est conseillé d'utiliser le menu Ajout/Suppression de Programmes afin que le système copie l'ensemble des clés du registre créées ou mises à jour lors de l'installation, ainsi que l'ensemble des fichiers INI de l'application. Par la suite ces paramètres seront mis à disposition de l'utilisateur lors de l'exécution de l'application.
Le second point concerne le fichier de configuration SAS qui nécessite certaines modifications.
- SASUSER
Cette option doit pointer vers un répertoire propre à chaque utilisateur. Pour ce faire on effectue un « mapping » dans le script de connexion USRLOGON.CMD afin d'affecter un Yvon LOUARN Département Support Clients - SAS Institute France Copyright (c) 2000 SAS Institute Inc. Cary, NC, USA. All rights reserved. disque logique à chaque utilisateur. Ce disque sera nommé par une lettre unique U par exemple, mais chaque disque U pointera sur un répertoire propre à l'utilisateur. Exemple de commande dans USRLOGON.CMD : SUBST U : C:\Utilisateurs\%USERNAME% Il suffit ensuite (normalement fait lors de l'installation) de vérifier la ligne de commande dans le fichier CONFIG : -SASUSER U:\SASUSER
- WORK
Il faut prendre soin avant l'installation de créer un espace disque suffisamment important pour que tous les utilisateurs puissent écrire leurs fichiers temporaires.
Exemple : -WORK W:\SASWORK Ainsi chaque client utilisera un répertoire W:\SASWORK\_TDnum où num représente le numéro du processus SAS.
D'autres paramètres peuvent être modifiés afin d'améliorer les performances.
- NOSPLASH
Cette option évite l'affichage du premier écran lors du lancement du système SAS. Ce qui peut paraître anodin permet de diminuer le trafic sur le réseau en supprimant l'affichage de cette image.
- SORTSIZE
On peut spécifier ainsi la taille mémoire qui sera utilisée lors des tris. Quand le système ne dispose pas d'assez de place il utilise l'espace temporaire de la WORK. La vigilance est donc de mise pour éviter avec une valeur trop forte un manque de mémoire, à fortiori l'utilisation du système de pagination, ou avec une valeur trop basse un engorgement au niveau des disques (remarque : l'option TAGSORT permet de limiter le volume du tri).
Ce type d'architecture peut s'avérer judicieux, notamment lors de la mise en place d'une
application en mode Client/Serveur, telle que le produit Enterprise Minerâ ou encore CFO
Visionâ. On sait en effet que ce type d'application ne peut être présente que sur un réseau
local, disposant d'une forte bande passante.
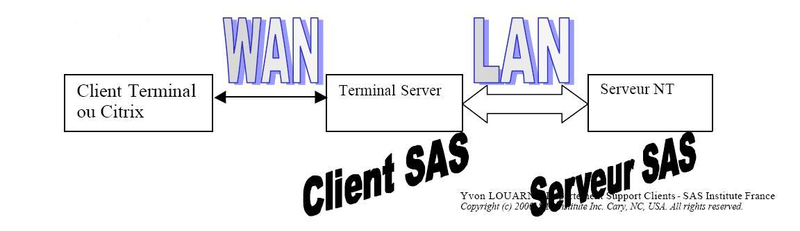
Comment faire quand les clients se trouvent éloignés, reliés au serveur SAS Enterprise Miner
par un WAN ? Dans ce cas l'installation du client Enterprise Miner sur un serveur Terminal ou
Citrix intermédiaire est une solution viable, car seuls les affichages écran sont envoyés sur les
postes des utilisateurs. Tous les traitements Client/Serveur demeurent sur le LAN.
Schéma de principe :
IV. La mise en oeuvre des sécurités▲
IV-A. Authentification transparente▲
En terme de sécurité la première nouveauté est sans doute le support de SSPI : Security Support Provider Interface, qui permet l'authentification « transparente » d'un utilisateur sur une autre machine. Le module SAS/CONNECT devient très aisé d'utilisation. Prenons par exemple le programme suivant : on établit une connexion sur le Spawner SPAWNYVL qui est sécurisé.
options comamid=tcp remote=frayvl.spawnyvl autosignon=yes;
rsubmit;
data a;a=1;run;
endrsubmit;
Et examinons la log correspondante :

IV-B. Les options USER et PASSWORD▲
Par contre, si l'on souhaite utiliser un autre contexte utilisateur sur le serveur, de nouvelles options USER et PASSWORD sont désormais disponibles. Contrairement au positionnement de la variable d'environnement TCPSEC, ces options ne sont valables que le temps de la connexion et la sécurité est donc accrue. Le module SAS/SHARE supporte également ces options.
Exemple de lancement d'un serveur SHARE sécurisé :
1- Exécution sur le serveur nommé Musset.
%LET TCPSEC=_SECURE_;
OPTIONS COMAMID=TCP ;
LIBNAME Clients ‘c:\SASV8\Clients' ;
PROC SERVER ID=shrV8 AUTHENTICATE=REQ; RUN;
2- Exécution sur le client
LIBNAME LIBCLI SLIBREF=Clients USER=frayvl PASSWORD=_PROMPT_
SERVER=Musset.shrV8 ;
Remarque : l'option USER peut être définie sous la forme Domaine \Compte, ce qui évite l'utilisation de l'option AUTHSERVER.
IV-C. Le cryptage avec ou sans le module SAS/SECURE▲
On ne peut pas parler de sécurité sans aborder le module SAS/SECURE et les différentes méthodes permettant de crypter les échanges : RC2, RC4 … En mode Client/Serveur, il faut que l'option NETENCRYPTALGORITHM soit positionnée sur le client et sur le serveur.
Concernant ce dernier, c'est une nouvelle fois le programme Spawner qui est mis à contribution.

IV-D. Franchissement d'un Firewall▲
Des modifications ont été apportées sur la connexion TCP afin d'apporter une plus grande souplesse pour qu'une application Client/Serveur puisse franchir un Firewall.
Ces changements apparus dans la version 8 ont été également portés en version 6.12 TS065. Il s'agit d'une option positionnée lors de l'installation du programme Spawner et nommée INHERITANCE.
Qu'est-ce que le « Socket inheritance » ?
Cette fonctionnalité permet à la session SAS, démarrée par le service Spawner, d'hériter de la socket TCP avec laquelle ce dernier communique avec la session SAS cliente. Cette nouvelle socket est ensuite utilisée pour communiquer avec le client.
Cela signifie en clair qu'un numéro de port unique est attribué pour toutes les connexions. Avant cela si vous aviez un nombre C de connexions, C+1 ports étaient utilisés : 1 port pour le programme Spawner + C ports pour autant de connexions clientes. Chaque client peut désormais communiquer à travers SAS en ouvrant leur propre socket pointant sur un numéro de port.
Il suffit donc de déclarer un numéro de port unique dans votre Firewall, celui utilisé par le programme Spawner.
Dans la pratique …
Vous devez déclarer un port dans votre Firewall qui devra être lié au port sur lequel vous désirez vous connecter, c'est à dire celui du Spawner. Ce mapping fera en sorte que chaque connexion externe utilisant le port 2500 sera routée vers le port 5400, par exemple. Ce port 5400 sera utilisé par le Spawner, programme démarré avec l'option INHERITANCE. Vous pouvez, bien entendu, effectuer un mapping sur le même numéro de port.
Voyons un exemple :
1- Déclaration du service Spawner dans le fichier SERVICES
spawnyvl 5400/tcp # Spawner Frayvl
2- Installation du programme Spawner en tant que service NT

3- Exécution du programme client
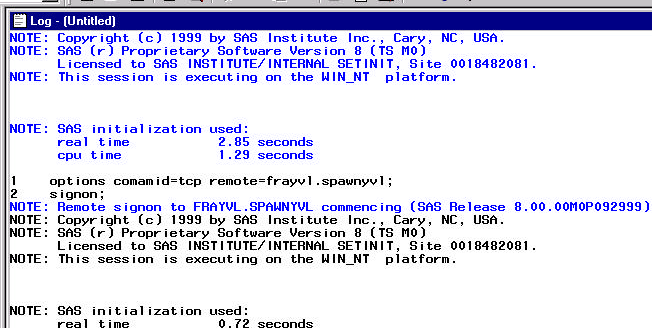
NB : Nous noterons au passage qu'un script de connexion n'est pas nécessaire. La saisie du nom de l'utilisateur et du mot de passe ne sont pas nécessaires.
Les options PORTFIRST et PORTLAST (TCPPORTFIRST et TCPPORLAST) sont également le moyen de franchir un Firewall. Ces options permettent de définir une plage de ports disponibles lors de la connexion.
V. Conclusion▲
En terme de performance, les fonctionnalités ne manquent pas pour améliorer le fonctionnement de votre application. MPCONNECT est un moyen simple d'exploiter au mieux des serveurs avec plusieurs processeurs. Notons que le produit SPD Serverâ est un produit idéal pour tirer encore davantage profit de votre serveur : il permet de paralléliser l ‘ensemble des accès aux données.
Le choix du type d'architecture est également un élément déterminant : centralisée ou non ? Les critères qui détermineront vos choix sont nombreux, mais dans tous les cas le système SAS s'intègrera rapidement à ce type d'architecture. Les produits orientés métier tels Enterprise Miner ou CFO Vision sont autant d'outils tirant profit des environnements Citrix et autre.
En dernier lieu les applications et les données pourront être sécurisées. J'évoque dans ce document la sécurité lors des connexions et du transfert d'informations. Le système de fichiers NTFS demeure le plus adapté pour protéger vos tables, catalogues. Les produits SAS s'appuient sur cette sécurité système.
VI. ANNEXE : Programme de test utilisé pour le MPCONNECT▲
Les modifications par rapport au code d'origine sont indiquées en gras
options fullstimer ;
options autosignon=yes;
options sascmd='sasv8';
data _null_ ;
host=sysget('HOST') ;
call symput('numloop',compress(trim(scan("&sysparm",1,"."))));
call symput('datsz',trim(scan("&sysparm",2,"."))) ;
call symput('host',trim(host)) ;
run ;
%macro benchds(numrecs);
libname foo v8 '/tmp';
data foo.tstdata;
/* create a data set with 110 variables and obs equal value of numrecs passed into the macro */
%mend ;
%benchds(&datsz) ;
%global time1;
%macro pretime;
data _null_;
time=put(time(),6.);
call symput('time1',time);
run ;
%mend;
%macro postime(sec);
data _null_;
time=time()- %str(&time1);
put '*';
put "******time elapsed(&sec) = " time 6.;
put '*';
run ;
%mend;
%macro shutdown() ;
%local runid;
%let runid=1 ;
%let remsessions=;
%do %while(&runid le &numloop);
%let remsessions=&remsessions rem&runid;
%let runid=%eval(&runid+1) ;
%end;
waitfor _all_ &remsessions;
%postime(0);
%let runid=1 ;
%do %while(&runid le &numloop);
proc printto log="mploop&runid..log"
print="mploop&runid..lst" new ; run;
rget rem&runid;
signoff rem&runid;
%let runid=%eval(&runid+1) ;
proc printto; run;
%end;
%mend ;
%macro startup(subsys) ;
%pretime;
proc datasets library=work ;
delete stats1 stats2;
quit;
%put APR HEADER os=&sysscp;
%put APR HEADER host=&host;
%put APR HEADER ver=&sysvlong;
%put APR HEADER subsys=&subsys;
%put APR HEADER numobs=&datsz;
%put APR HEADER duration=&numloop;
%mend ;
%macro runtest(runid) ;
/****************************************
* create a new MP CONNECT session to
* handle this iteration
****************************************/
rsubmit rem&runid wait=no;
libname foo v8 '/tmp';
/****************************************
* Step CONTENTS_2
****************************************/
proc contents data=foo.tstdata;
/****************************************
* STEP SORT_3
***************************************/
proc sort data=foo.tstdata out=out1 tagsort ;
by descending x1_10 stname8 ;
run ;
/****************************************
* STEP FREQ_4
****************************************/
proc freq data=foo.tstdata;
tables stname20 onein10 onein100 onein1k ;
title 'proc freq ';
run ;
/****************************************
* STEP SUMMARY_5
****************************************/
proc summary data=foo.tstdata print ;
title 'proc summary full data set ' ;
var _numeric_ ;
run ;
/****************************************
* STEP SUMMARY_6
****************************************/
proc summary data=foo.tstdata print ;
title 'proc summary three state names subsetted by where clause' ;
var _numeric_ ;
where stname20='ALABAMA' or stname20='CALIFORNIA' or stname20='TEXAS' ;
run ;
/****************************************
* STEP DATA_7
****************************************/
data temp;
set foo.tstdata;
if stname20='ALABAMA' or stname20='CALIFORNIA' or stname20='TEXAS';
run ;
/****************************************
* STEP SUMMARY_8
****************************************/
proc summary data=temp print ;
title 'proc summary three state names subsetted by data set' ;
var _numeric_ ;
run ;
/****************************************
* STEP DATA_9
****************************************/
data _null_;
set foo.tstdata;
where onein100='y';
run ;
/****************************************
* STEP DATA_10
****************************************/
data _null_ ;
set foo.tstdata;
if onein100='y' ;
run ;
/****************************************
* STEP DATA_11
****************************************/
data _null_ ;
set foo.tstdata;
where x1_1000=9 or x1_1000=99 or x1_1000=999 ;
run ;
/****************************************
* STEP DATA_12
****************************************/
data _null_ ;
set foo.tstdata;
run ;
/****************************************
* STEP TRANSPOSE_13
****************************************/
proc transpose data=foo.tstdata (keep=f1 x1_10) out=trans ;
by x1_10 notsorted ;
var f1 ;
run ;
/****************************************
* STEP SORT_15
****************************************
proc sort data=foo.tstdata out=out1 ;
by x1_100 stname8 ;
run ;
****************************************
* STEP SUMMARY_16
****************************************/
proc summary data=foo.tstdata;
title 'proc summary full data set ' ;
var _numeric_ ;
output out=stats1 ;
run ;
/****************************************
* STEP SUMMARY_17
****************************************/
proc summary data=foo.tstdata;
title 'proc summary three state names' ;
var _numeric_ ;
where stname20='ALABAMA' or stname20='CALIFORNIA' or stname20='TEXAS' ;
output out=stats2 ;
run ;
/****************************************
* STEP SUMMARY_18
****************************************/
proc summary data=temp ;
title 'proc summary three state names' ;
var _numeric_ ;
output out=stats2 ;
run ;
endrsubmit;
%mend ;
%macro duration();
%local runid ;
%let runid=1 ;
%do %while(&runid le &numloop);
%runtest(&runid) ;
%let runid=%eval(&runid+1) ;
%end;
%mend;
%startup(Perf);
%duration ;
%shutdown;